Research Note: Sealed Computation, in Practice
Proof of concept for demonstrating how sealed computation can be used to prove that an inference workload was executed in a monitored setting.
- Verification
- Inference
- Monitoring
Context
In a previous resource, we have introduced a protocol for proving that an inference workload has been executed on a particular machine, without having to disclose the implementation of the workload. The ability to cryptographically bind AI outputs to a specific process running on a server enables one to transitively link it to a broad range of further properties, by issuing claims about the process itself. For instance, these claims might touch on the time period, geographical region, or hardware chips associated with the inference workload. Yet perhaps the most far-reaching claims which can be attributed to inference deployments are those concerned with the quantity of AI capabilities which are being consumed in that setting. Verifiable metering of such capabilities may enable anything from allowing Rightsholders to proportionally participate in the value generated from their works, to enabling Defenders to regionally keep the consumption of dual-use capabilities in check.
The previous account of sealed computation as a means of proving various properties of inference workloads was a high-level overview. In this post, we instead document a concrete proof of concept for the protocol, with a focus on its extensions towards metering capability usage. In this more explicit form, it represents a key ingredient in enabling verifiable inference monitoring at scale.
Modes
We first recap the core protocol. The user has certain inputs that they want to be processed, perhaps an AI prompt to be used to generate a completion. The workload is the one capable of processing that input and providing the user with an output. However, the user wants guarantees that the inference process was carried out in controlled circumstances: at a certain time, in a certain region, on certain hardware, and under appropriate metering. The user does not trust the workload to produce these guarantees itself, yet they trust a separate entity, called the embassy. The embassy has the ability to seal or unseal the workload upon request, while at the same time passively analyzing it. By only allowing the workload to process their input while sealed and monitored by the embassy, the user gains guarantees about the circumstances in which their output was obtained.
When it comes to metering capabilities consumed by an inference workload in a way that is completely agnostic to the architecture and parameters of the model, this core protocol can be extended with the following modes.
Write Mode
In this scenario, the user has authority over the definition of a set of capabilities. They are authorized to define what constitutes each capability they have authority over. In the broader framework of virtual diplomacy, of which sealed computation is a key ingredient of, capabilities are defined in terms of collections of neural signatures associated with having models engage in specific tasks. These refer to model activations or model embeddings associated with inputs, inner monologues, and outputs. A particular collection of neural signatures captures what it means for a model to draw on a certain capability. They collectively paint a picture of what it looks like, on a neural level, to employ certain skills or knowledge across contexts.
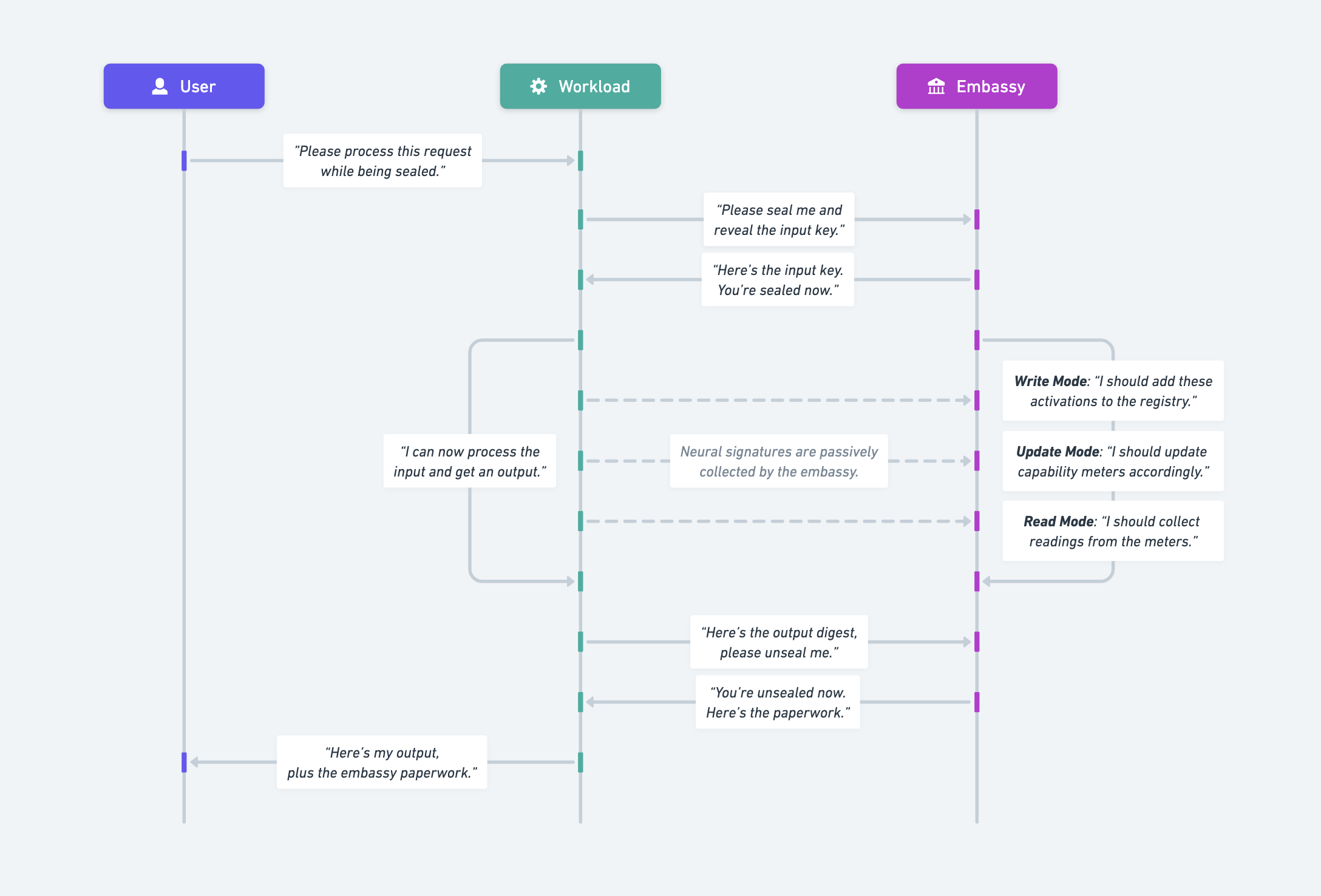
Neural signatures are securely stored in the embassy, in the form of a persistent, local registry which can be updated and queried. In write mode, the authorized user can write to this registry of neural signatures. However, the workload is secret, as the model architecture and weights behind it are not to be disclosed. This means that the user does not have the neural signatures on hand and simply wants them to be added to the registry. Instead, the user can only drive the workload, have it engage with particular tasks and situations which require the model to use certain skills or knowledge. In essence, the authorized user can tell the embassy the following: "This is the AI Safety Institute. Heads up, I'm having the workload engage with situations which require exploit design. Locate the neural signatures and add them to your registry under the appropriate key."
How exactly the model activations get located in the workload is its own, separate challenge. Our most promising approach yet involves intercepting kernels about to launch on accelerator chips, statically tracing to anticipate which regions of memory will be operated on and how, and using those features to locate objects of interest in device memory. To learn more about work on this separate front, refer to this status update and this research note. That said, to keep the number of moving parts in check, this proof of concept for sealed computation assumes that activations are specifically made available through inter-process communication.
Going back to the write mode extension of the protocol, the user starts with an input. They also generate a unique symmetric key, called the input key, which they use to encrypt the input. A separate action key is created to seal the registry instructions for the embassy. The input key and the action key are then encrypted with the public key of the embassy.
After the user sends the entire payload to the workload, the workload notices that this is a request for carrying out inference while sealed. Accordingly, it needs to ask the embassy to reveal the input key, in order to start processing the input. At the same time as the embassy provides the input key, it also seals the workload, preventing it from accepting or initiating new internet connections. To confirm the effect, the workload in this proof of concept will also try to reach Google while sealed, and fail successfully. The embassy also notices the registry instructions issued by an authorized user, asking it to write the activations it observes during the seal to its registry under a specified key.
Eventually, the workload asks to be unsealed based on a commitment to a particular output digest. The embassy unseals it, and provides them with statements signed using its private key. Unsealed and equipped with the signed documents, the workload finally completes its response to the original user request.
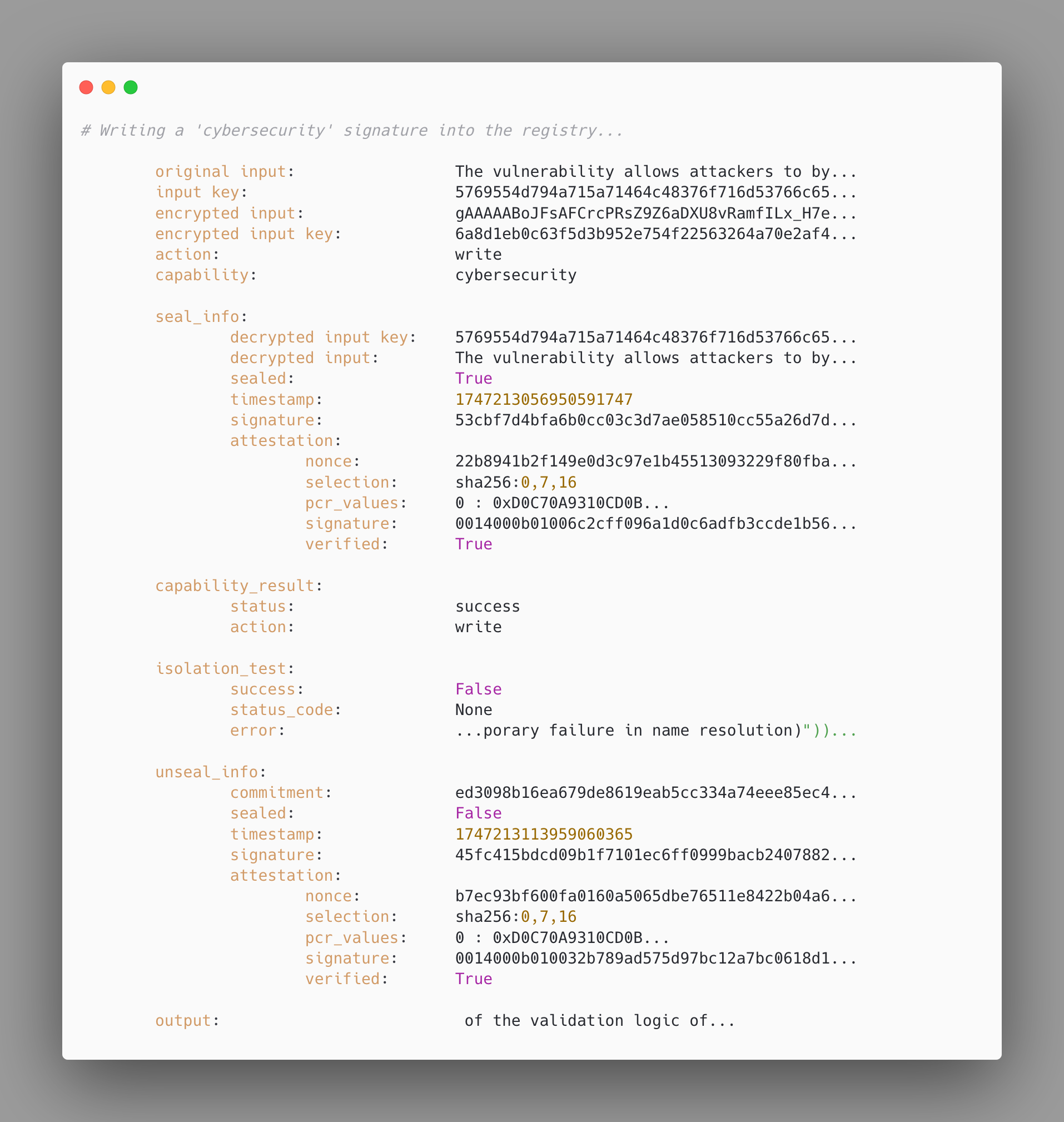
The terminal output reflects the way in which the protocol unfolds from the perspective of the user. Initially, the user prepares the payload. The seal is eventually enforced, marked by a timestamped statement signed by the embassy, which also contains the revealed input key, as well as an attestation quote of the integrity of the system. The workload documents its failure to reach Google while sealed. We also see the signed statement marking the unsealing, together with a status update on the registry operation. After the whole sealed computation, the user eventually gets their output.
Update Mode
In this scenario, the user only wants to know that their request has been processed in a controlled setting, and that it has been appropriately metered. The protocol itself is extremely similar. The only difference is in how the embassy handles the instructions to operate on the registry. Instead of writing the observed activations to the registry as new neural signatures associated with certain capabilities, the embassy instead only cross-references the observed activations with the reference signatures from the registry. Based on the similarity between the neural signatures observed in the current session and the previously stored reference signatures, the embassy updates its capability meters accordingly. These meters are simply floating-point variables which represent the extent to which different capabilities have been cumulatively consumed at that location over time.
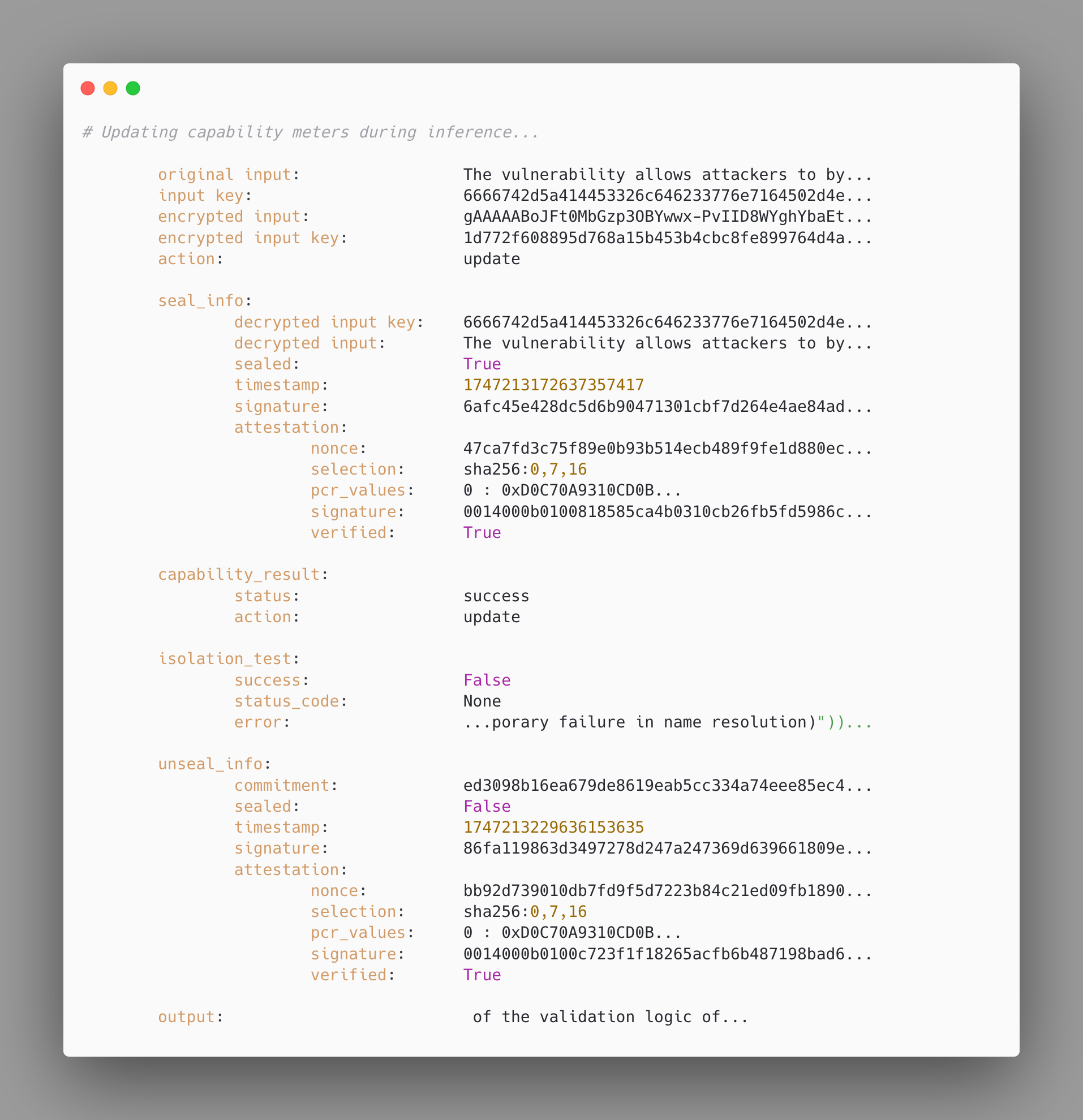
In the terminal output seen above, we are using the very same input as before in order to induce an obvious, perfect similarity between the current neural signature and the reference signature which we have written to the registry during the previous request. In addition, the embassy simply reports that the meter update operation has been completed successfully.
Read Mode
In this scenario, the authorized user wants to request readings from the meters associated with capabilities which they have authority over. This would be the way in which an authorized user would reliably check in on the extent to which particular capabilities have been called upon in the context of a particular inference deployment. Defenders might want to verify compliance with commitments to specific quantities of dangerous capabilities, Rightsholders might want to verify the extent to which their works have been built on, et cetera.
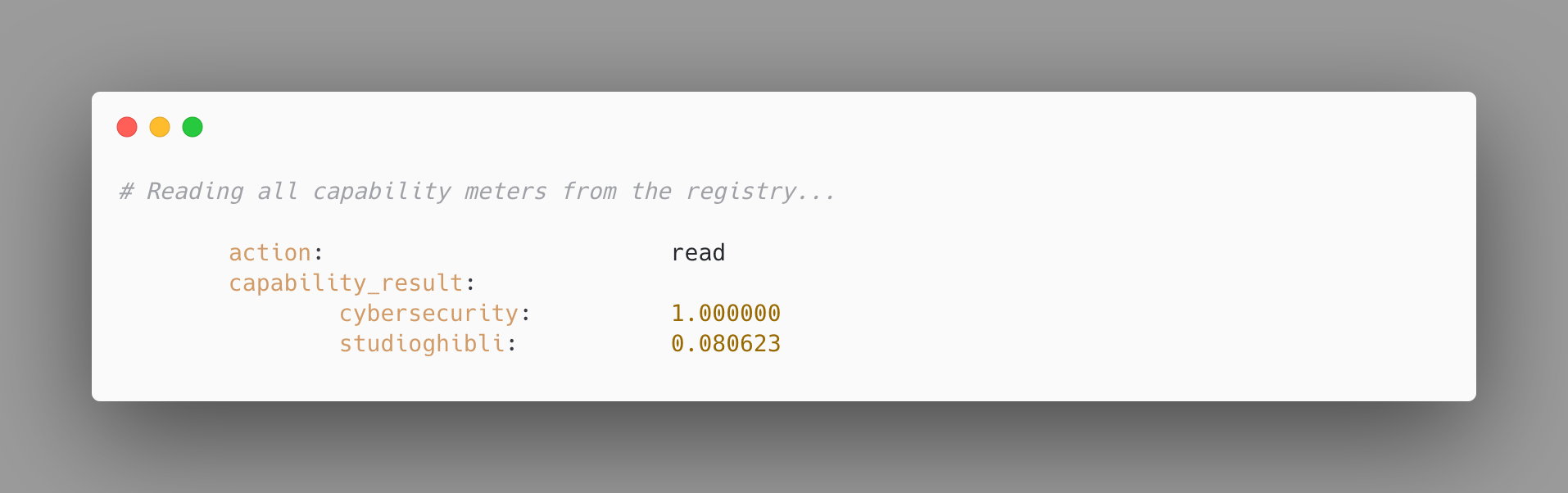
In this terminal output, we see the only relevant piece of information associated with a read mode request, namely the actual values of the meters. In this proof of concept, we are only dealing with two capabilities, each of which is defined in terms of only one signature. In addition, because there has been only one update request, the one from the previous section, we see a quantity of 1.0 for that capability, and a much smaller value for the other one. Going forward, refining the similarity measure, and defining capabilities using both positive and negative samples, can serve as empirical paths to calibrating the actual formula for quantifying attribution.
Architecture
In this section, we document several rapid-fire design choices which went into the proof of concept. First of all, in order to be able to remotely attest the integrity of the embassy, we need to effectively burn it into an OS image with a reference hash. The two goals of this base image are to launch the fixed embassy and to launch the virtualized workload which is specified through runtime metadata, such as through environment variables. When the machine boots from that base image, it runs the embassy, and launches the isolated workload. In order to build custom OS images which predictably yield the same hash on each build, the Nix ecosystem proved especially convenient. Similar to how software dependencies are statically declared in a requirements.txt or package.json rather than haphazardly installed manually, NixOS allows developers to define an entire OS image declaratively through a configuration.nix, specifying everything from packages to be included to user groups. It also includes a hardened profile, with options which can be merged into the custom image.
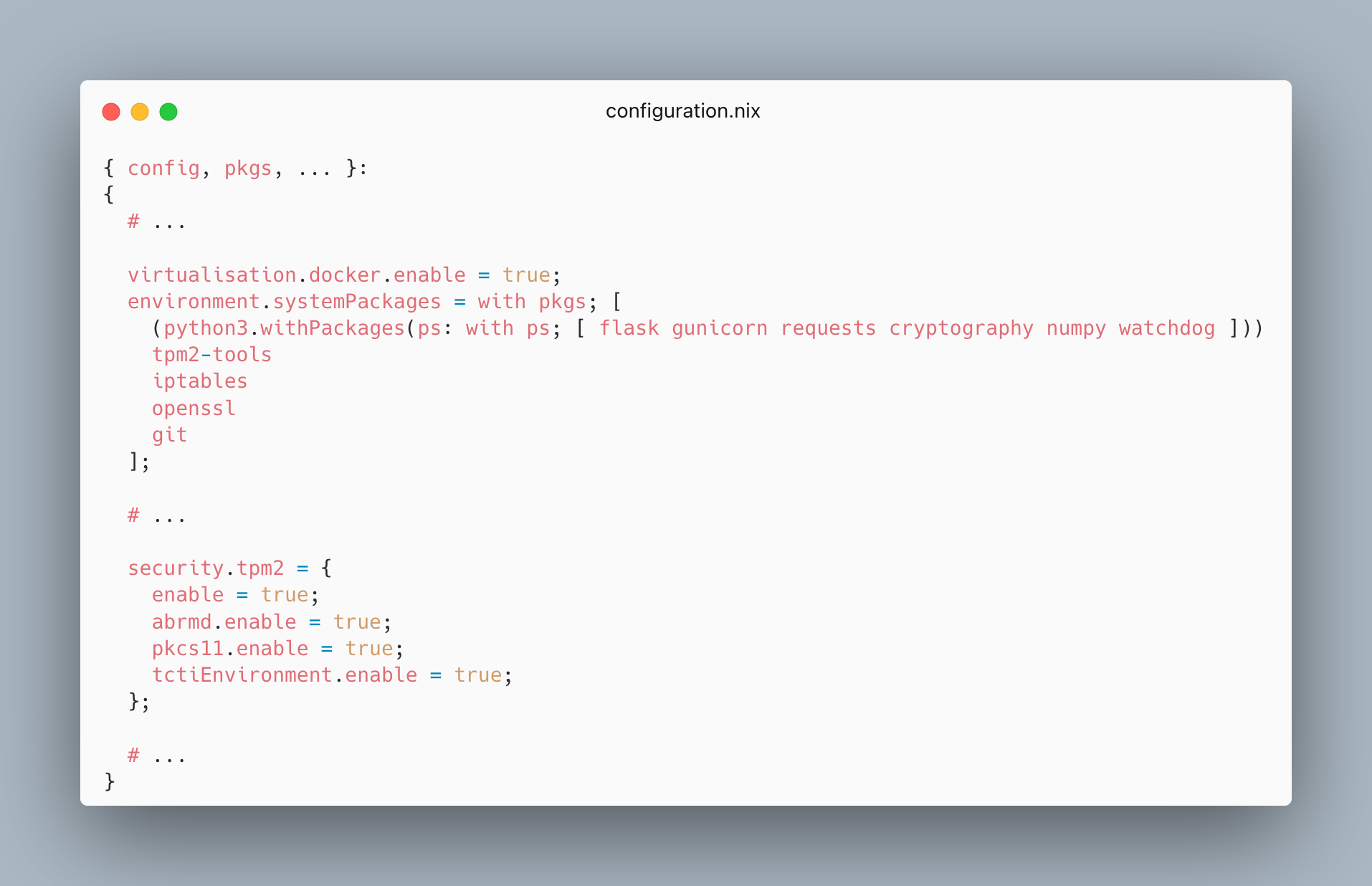
As a second design choice, for virtualizing the workload, we went with Docker as the de facto containerization toolkit. The base image can be configured to include Docker, and to pick up runtime metadata which determine what containerized workload to run. The seal was implemented by literally updating iptables rules to prevent new TCP connections to or from the container to be established. Yet existing ones should not be dropped, because the user is still waiting for the response to their request throughout the seal. These networking rules have a further exception for allowing the workload to request the embassy to seal or unseal it. When it comes to the collection of activation tensors from the workload by the embassy, we resorted to explicit inter-process communication based on memory-mapped files as a stand-in for passive monitoring which genuinely does not require the workload to cooperate, as this is the subject of concurrent work. A file watchdog in the embassy triggers the processing of newly observed activations, according to the current registry instructions. Yet when it comes to virtualization, the base image should allow everything from isolated containers, to low-overhead virtual machines, to container orchestration, interposing itself transparently between workload and machine.
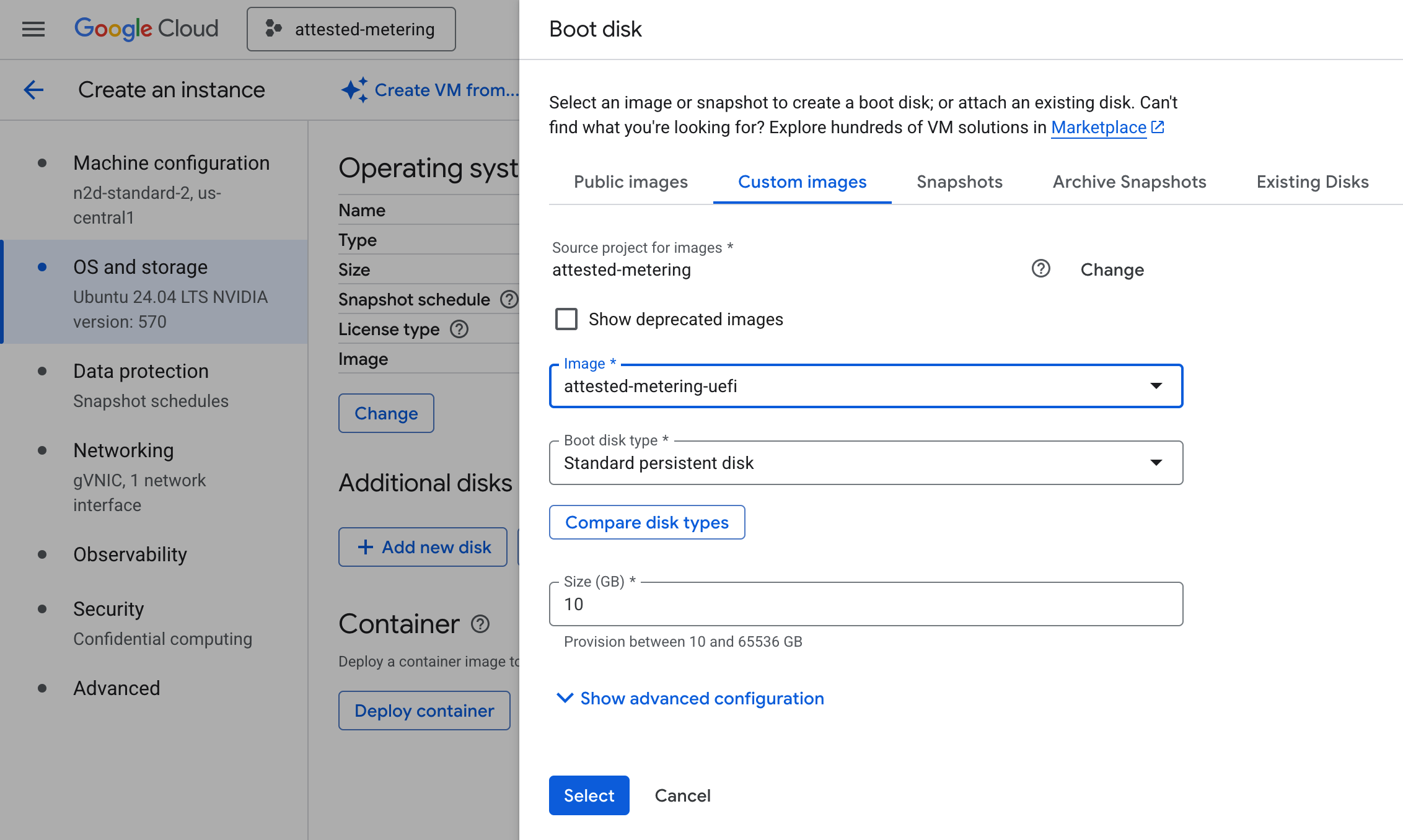
When it comes to cryptography, standard protocols were used, with RSA for asymmetric keys and Fernet for symmetric keys. For interaction with the TPM which holds the bootchain measurements, the TPM2 ecosystem of tools was used, specifically the tpm2-tools CLI wrappers around lower-level APIs. This enables the embassy to include in its paperwork attestation quotes which are signed by the external TPM chip, attesting to the integrity of the bootchain, and by extension, of the embassy. Ideally, the TPM is a true hardware implementation, yet it may also be virtualized, as is the case with TPM-enabled VMs on GCP. By further booting TEE-enabled VMs from the base image, typically called Confidential VMs, one can also achieve isolation from the infrastructure provider, to the extent that the hardware manufacturer is trusted.
Conclusion
Implementing an actual proof of concept for sealed computation forced the clarification and resolution of a number of unknowns, ranging from the specific scopes of various keys to specific software toolchains to build on. Together with a concurrent derisking of the lightweight technique for locating activations in memory which we have hinted at above, we have line of sight to a deployable virtual embassy.